situation
Prolifration of loT and moblie devices——>a substential DDoS
Network wide heavy hitters
Should aggregate the information observed at each switch to identify flows whose exceeds a global threshold
1. goal
- To identify the elephants flows that exceed a global threshold
- To estimate their packet counts
2. protocol
2.1 protocol
Sampling rate: r = 1/k We consider flows of fewer than 5 packets as mice, sampling rate is 1/5
Local threshold: 𝜏 > 1/𝑠, 𝜏= 𝜖T/k
Global threshold: R =kr/𝜖 message received is netwide heavy hitter
2.2 Prohibility report
- 交换机数量增加,准确率会下降
- 别的没报告的交换机会有剩下的数据包让中心报告器估算的交换机数量不准,因为有”blind spot“
- message数会随着网络中交换机的数量增长
- 降低本地阈值𝜏到很小,会增加message数量
- 使用概率报告,可以让误差边界与交换机数量无关,但会需要保存无限状态和大量计算
2.3 Spatial locality
前面的protocol会假设所有交换机都是平等的
但是,大多数流量具有局部空间性:某一个流只有部分交换机观察得到
这会导致更低的本地阈值,和更多的message数
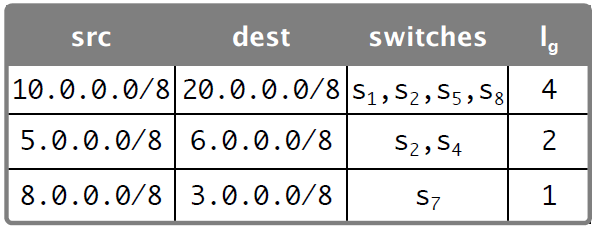
引入locality parameters 参数lf,代表the number of switches that denote flow f
Sampling rate: rf = 1/k We consider flows of fewer than s packets as mice, sampling rate is 1/s
Local threshold: 𝜏f > 1/𝑠, 𝜏f= 𝜖T/lf
Global threshold: Rf =lf*rf/𝜖 message received is netwide-heavy hitter
但是locality of switch也是会因为failures和routing updates而改变
每个交换机一直都知道flows expects to observe
当遇到unexpected flow会给coordinator发送”HELLO”信息
coordinator拿到f和s的信息,coordinator分别计算𝑟𝑓, 𝜏𝑓
给所有观察到f的交换机修改参数(为了避免瞬时改变,仅当观察到流f的交换机集合Sf变成两倍之后,再更新参数)
2.4 data structure
- 之前的原型需要在可编程交换机上存储每流阈值,但是内存太小
- 因此,需要解耦:数据包计数粒度, locality must obseved的粒度
- 存储报告参数(coarser granularity): at the granularity of goups of related flows
- 存储计数器(finer granularity): for the sampled flow
- 有个小问题:每个flip的浮点数运算
- 将浮点值表示成一个无符号整数(0 < 𝑖 ≤ 1.0),然后使用packet header fields计算32bit哈希值,检查是否比2^32*i小
3. summary
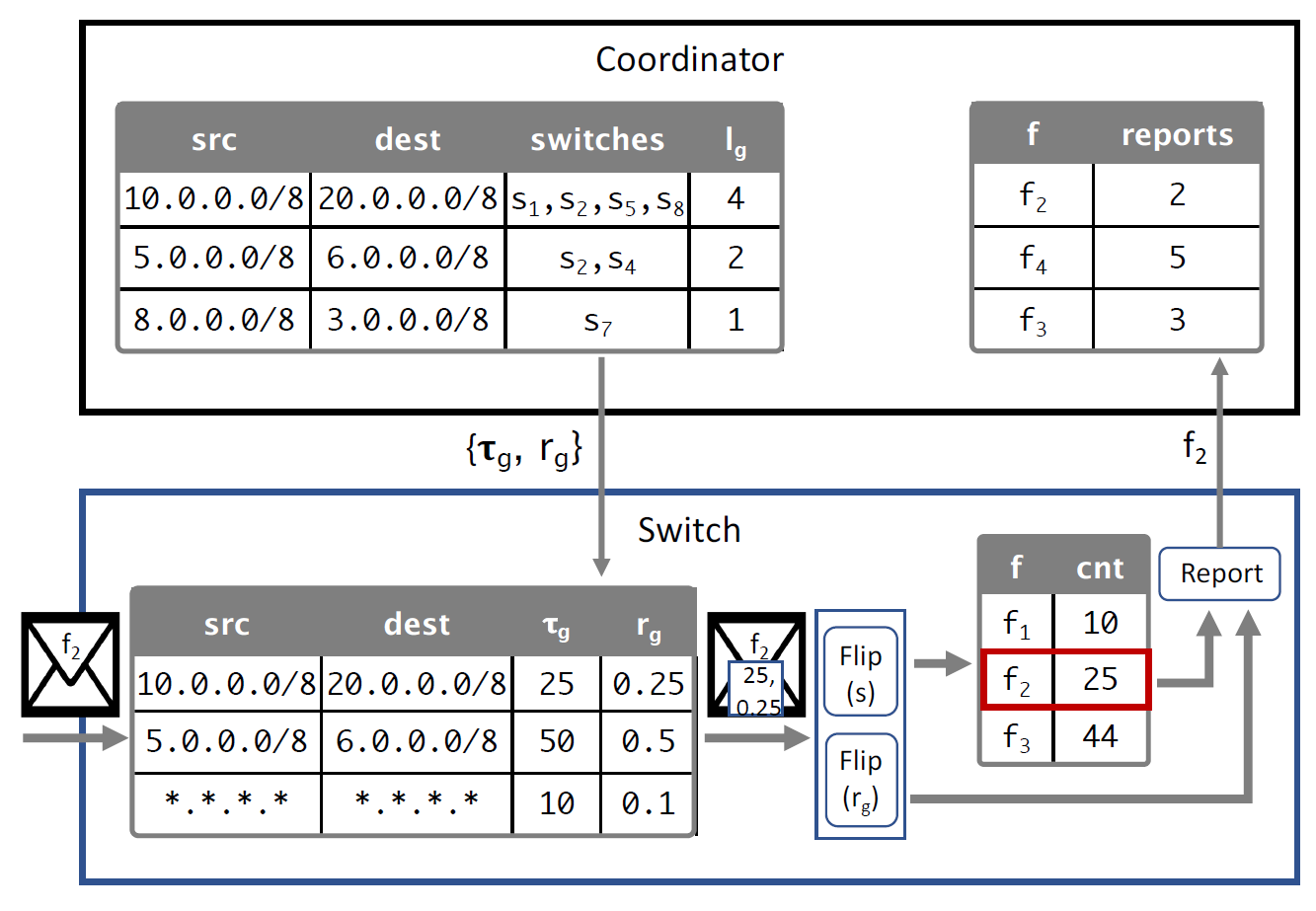
flip1(based on sampling probability): 交换机以1/s的采样率采样,过滤掉mice, 如果采样那么flip1 = true
如果flip1==true, 读取阈值+概率表

如果是expected flow,获取流对应的阈值和概率储存在register
如果是 unexpected flow,给coordinator发送“HELLO”信息, coordinator拿到f和s的信息,coordinator更新𝑙𝑓, 计算𝑟𝑓和𝜏𝑓给发送”HELLO“的交换机。(we update the locality parameters for a flow only when the size of 𝑆𝑓 doubles. 𝑆𝑓 是observe 流f的交换机集合)
检查在不在data structure D中
- 如果在,counter +1
- 如果不在,counter = 1/s
flip2(based on reporting probability): 如果flip2 == true, 交换机reset counter,并report给controller,controller修改计数table

4. experiment
flow key: 五元组
time window: Duaring a time window of 5 seconds, 5 million packets, 270K unique flows
switch num: K = 10 超过10个会导致更小不真实的workloads
local switch num:
L = 2 每个流只出现在两个交换机上
单源入口的primary /alternate relationship, p = 0.95
global threshold: T 全局阈值99.99百分位
Sampling rate: 0.001(这个速率下通信)
an approximation factor of 𝜖 = 0.1
评价指标: F1
5. question
- 还是有个问题没有解决:
- f3在B交换机20个报告一次,报告了4次(80个包),剩下19还差一个所以没有report;
- f3在A交换机上被当作mice过滤掉了,
- 实际上全局来看f3是一个需要report的elephant

- 在现有的改进策略下。。想一想
这个问题文中给的解释就是因为Carpe generates a report with probability each time packets are observed for a sampled flow, allowing Carpe to achieve an error bound that is independent of the number of switches, 就是说Carpe controller收到的report数量得到的某一个流的估计,已经和data plane有多少个交换机无关了。(参考论文 Algorithms for Distributed Functional Monitoring )