Motivation
不同流量模式需要不同ECN
静态ECN不能很好工作
调整参数复杂且耗时不同流量模式需要不同ECN
ACC
formalization
Markov Decision process(MDP):
$ M =
$ M =
- S: state space
- A: a set of actions
- $P(S{t+1}|S_t, a)$: probability of action a$ \in A$ at state $S_t$ will lead to state $S{t+1}$
- $R_{S,a}$:intermedia reward after executing action a from state $S_t$
- $\gamma \in [0,1]$:discount factorthat controls how much we fractor immediate rewards over those from distant future
Goal:
最大化 discount accumulated rewards
- 学习从S映射到A的最佳策略$\pi^$:$ \pi^=argmax{\pi}E^\pi(\sum{t=0}^{\infty}\gamma^tr_t) $
- state-action value $ Q^*(S,a)=max\pi E^\pi (\sum{k=0}^{\infty}\gamma^kr_{k+1}|S_t = S,a_t = a) $
ECN problem:
monitoring interval: $\Delta t$
in time interval:
- records the state(network statics) $S_t$
- takes an action(ECN configuration) $a_t$
- receives a reward $r_t$
formalization:
- state : agent输入的环境信息(即网络拥塞风险),
- 当前排队长度(Qlen)
- 每条链路的输出数据速率(TxRate)
- 每条链路的ECN标记分组输出速率($ txRate^{(m)} $)
- 当前ECN设置($ ECN^{c} $)
- action: $ a{t} = {K{max},K_{min},P{max}}_t $
- 当吞吐量大于1M,吞吐量对high marking threshold不敏感。为了减少状态空间,商品交换机中每个队列的最大缓冲区大小通常小于10MB,所以对ECN调整的action做离散化{1MB、2MB、5MB、10MB}
- high marking threshiold: $ K_{max} $
- 在短范围内设置多个间隔,实现对标记报文的细粒度调整,使用指数函数 $ E(n)=\alpha*2^n KB,n=0,…,9 ,alpha = 20$
- low marking threshold: $ K_{min} $
- marking probability: $ P_{max}$
- 当吞吐量大于1M,吞吐量对high marking threshold不敏感。为了减少状态空间,商品交换机中每个队列的最大缓冲区大小通常小于10MB,所以对ECN调整的action做离散化{1MB、2MB、5MB、10MB}
- reward:
- $ r = \omega_1T(R)+\omega_2D(L) $
- 定义为吞吐量throuput和时延latency之间的权衡
- $ \omega_1, \omega_2 $ 是利用率和时延的折衷权值,相加和为1,系统中设置$ \omega_1=0.7, \omega_2=0.3 $
- $ T(R) = txRate/BW $
- txRate是一个出口队列的平均吞吐量,即在$ \Delta t $ 内已经传送到链路的数据量
- BW是带宽,用来归一化吞吐量,表示链路利用率
- $ D(L) = 1-n/10 $

- L是平均队列长度,代表时延
- $ n = argmin(E(N)>L), n= 0,…,9 $
- $ r = \omega_1T(R)+\omega_2D(L) $
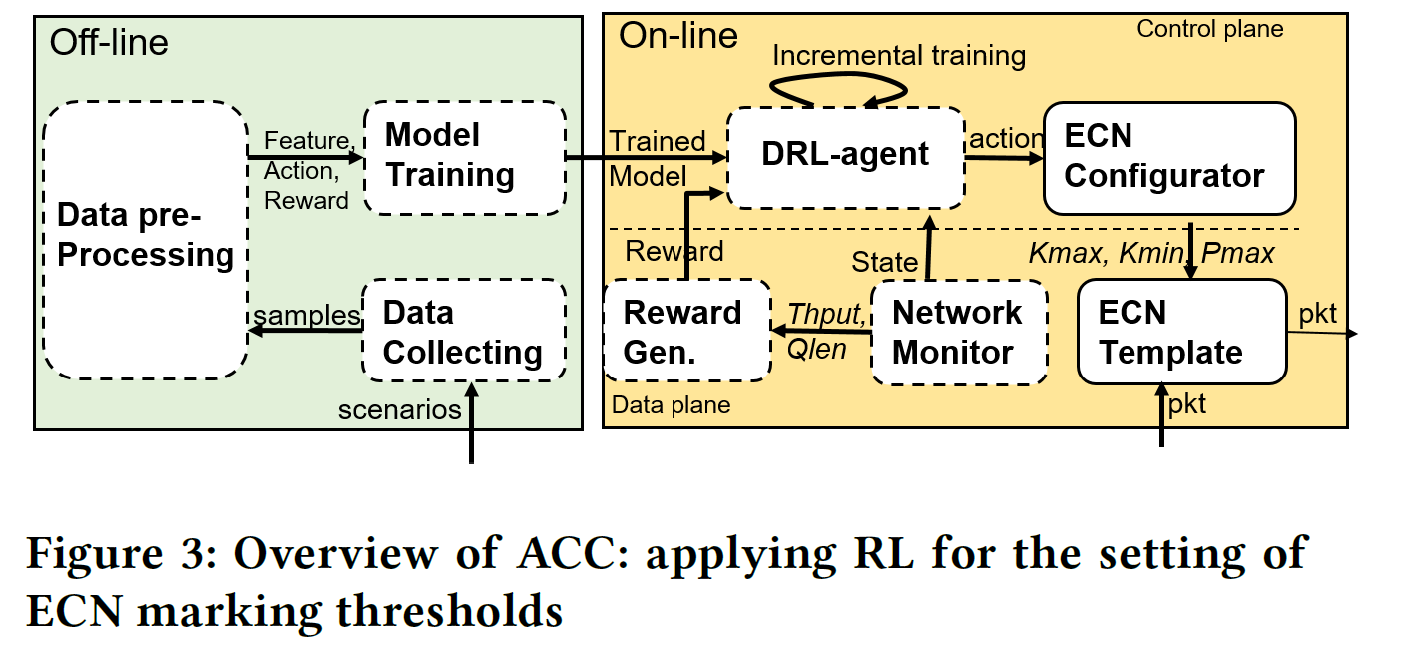
framework
- 离线:
- 根据收集的数据进行离线训练,得到预先训练好的模型
- 在线
- monitor state: 队列深度,吞吐量,流信息(ECN标记的分组的数量)
- RL-Agent(pre-trained Neutral Network)生成actions
- ECN confiuguration执行actions将ECN值映射到转发芯片的ECN模块中
- RL-Agent用rewards更新网络
- 集中式
- 集中式模型需要很久才收敛
- 一般需要several milliseconds 从所有交换机上收集信息
- 收集大量训练数据占很大的带宽
- 分布式
- 只靠本地网络状态,state action空间小,学习收敛速度快
- 只需要几mirco seconds
- 避免了数据传输